

Introducing Sporalyzer: A Tool for Analyzing Contract Size
The first tool for size analysis at the expression level.


EIP-170 introduced a contract size limit of 24kb. The rationale at the time was to mitigate a potential vulnerability wherein fixed gas costs are paid by users but miners/validators incur quadratic costs around disk reads, pre-processing the code for VM execution, and adding data to the Merkle Proof of the block’s proof-of-validity.
The current approaches to optimizing contract size are coarse (e.g., solc-size-plugin), profiling entire contracts rather than individual expressions. Thus there is no efficient way to gain insight into how each element of the contract contributes to the overall size. To understand the size contribution of individual expressions, current approaches require manually analyzing and A/B testing the Solidity code. This can be time-consuming and inefficient, especially for large contracts.
A Motivating Example
To better exemplify the issue of contract size and its unexpected occurrence, let's examine a hypothetical contract:
Large Contract Example - Ballot
In this contrived contract, we identify four factors that contribute to its excessive size:
Large Constants
Excessive Modifier Use
Numerous Entry Points
Extensive Error Strings
Solving the Size Problem
Now that we have fully introduced the size constraint problem, let's turn our attention to solving it. Although many Solidity developers have struggled with this issue, there is still progress to be made in automating the diagnosticcess. Indeed, even an ethereum.org post1 on the matter suggests that developers should just look for some problematic patterns and do their best to guess whether these might be the cause of the issue. We believe there is a better way.
We wanted to create a tool that would allow us to determine how much of the binary contract size was being generated for every function, or even every expression. For those familiar with tools for analyzing hard disk usage, such as WinDirStat, this might be the most intuitive comparison to what we wanted to build. This will allow us to triage the greatest sources of contract size, reveal potential surprise sources of contract size, and just generally understand which Solidity coding patterns are leading to sub-optimal code generation with respect to contract size.

The Building Blocks
First we will consider the resources that we have to work with. The solc compiler can produce a wide range of build artifacts when compiling smart contracts, and most of these are ignored by the vast majority of developers.
The exact set of artifacts generated by solc is configurable, and before we can look at the contents of some of these artifacts we will need to enable maximal solc output. This needs to be done because solc will only emit a basic set of build artifacts by default, but we are interested in seeing the full range of data that is at our disposal for helping to solve the contract size issue. We can enable the full solc output by editing the compiler configuration JSON file, as described in the Solidity documentation2.
In particular, we want to enable maximal output by using the * option for everything under the outputSelection configuration key.

Once we have made this change to the compiler configuration, we can rebuild our large contract and browse to the artifacts/build-info directory inside our project directory. Here we will find one or more JSON files that contain the complete output of solc, packaged as a monolithic JSON blob.

Now that we have as much data as possible to work with, let's take a closer look at some particular pieces that will be helpful to us.
Source Maps
In order to allow such dense code to be more easily debugged, source maps were introduced as a way to map the dense, inscrutable Javascript code back to the original source code, whether that be pre-minification Javascript or source code in some other language, prior to transpilation.
Solidity has adapted this concept to EVM code, using source maps as a way to provide a mapping between EVM bytecode and the original Solidity source code that was responsible for generating it. Although in this case the mapping is between bytecode and source code, rather than source code and source code as it was in web browsers, the concept is essentially the same. And indeed, the source map file format used by solc3 is nearly identical to that used in web browsers4.
A key property of Solidity source maps is that they allow us to associate a range of source code with every byte of EVM bytecode in our contract. Because the source map must be a linear and contiguous listing of bytecode to source mappings, every single byte of bytecode is accounted for in some way.
This potentially solves a large part of the contract size introspection problem, since we can now find the guilty code responsible for any given EVM bytecode in our contract. We just need to find a way to make this information legible in a manner that allows us to find the most problematic parts of our source code. But in order to do that, we need one more set of information.
Abstract Syntax Trees
In order to make the data from the source map useful, we need some way to associate it with specific Solidity language constructs, such as functions or individual statements. The source map itself only gave us some numbers that point to ranges of the original source code files, but these numbers by themselves are difficult to use when trying to answer questions like 'what is the largest function in my contract?' or 'how exactly did the change I just made affect the size of the generated code?'.
What we still need is some way to associate a source code range with the corresponding Solidity construct, as expressed in some machine-understandable form. Abstract Syntax Trees (ASTs) are the name given to this machine-understandable representation of the original source code. ASTs are the first thing generated by compilers before they actually start the process of figuring out the lower-level code to generate for a given program.
In the case of solc, it very helpfully includes a JSON representation of the AST of the compiler input within the overall build info that it outputs. This is, for every input .sol file, solc will include a JSON representation of the AST of that file inside the broader build info JSON blob. This AST data can be used to map source code range numbers to higher-level Solidity constructs like functions.




Contract Bytecode
The last piece of output that we need to make note of is the actual contract bytecode itself. This is needed because we will need to handle certain edge cases properly when counting bytecode size, such as PUSH instructions that use multiple bytes. The contract bytecode5 can also be found within the build info JSON blob.

The Analysis
Looking at all the data we have to work with, it should now be apparent how we can start to carry out a better analysis of contract size. At a high level, the process is very simple:
For each entry in the source map
Get the actual size of the corresponding EVM instruction from the bytecode (1 + n bytes for PUSHn, and 1 byte for every other opcode)
Find the corresponding leaf AST node based on the source range
Increment a size field in the leaf AST node, and increment a size field in every non-lead AST node going from the leaf to the root of the AST
This process will leave us with an AST that has every node annotated with a size value, including all the size value of all of its child nodes, along with any extra size that is not attributable to any more specific child node in the AST.
This might sound a little complicated, but an example will make it clear. Consider the following simple contract:
contract Simple {
function foo(uint bar) public view returns (uint) {
return bar = bar * 5;
}
function baz(uint quux) public view returns (uint) {
return foo(foo(quux));
}
}After our analysis has been performed, the root AST node will have a size field that is equal to the total size of the compiled code. That root AST node will have sub-nodes such as the FunctionDefinition nodes for foo and baz, which will have size fields that are equal to the entire size of the bytecode used to implement those functions (as far as solc is concerned anyway -- more on this below). But these FunctionDefinition nodes will have yet further sub-nodes for things like the individual statements inside the function (e.g. return bar = bar * 5;), and these in turn will have sub-nodes for the individual expressions that make up the statement (e.g. bar * 5).
It might seem intuitive to assume that the size field for a given non-lead AST node is just the sum of the sizes of its child nodes, but this is not actually always the case. In some cases there is EVM bytecode that cannot be associated with a more specific leaf node in the AST, but which can still be attributed to some intermediate node. In our example, we could imagine that the FunctionDefinition node for foo is actually a bit larger than the sum of the sizes of its child nodes, because there may be bytecode for stuff like the function prologie and epilogue, which are part of the function as a whole, but not any of the source expressions within it.
Another important note here is that our analysis is only as precise and accurate as the data that solc provides us. The source map data is not so precise as to always map every byte of EVM bytecode to the absolutely most specific range of source code. This means that some size may be attributed to non-leaf AST nodes that could in principle be attributed to a more specific node, deeper in the AST. But in practice this is not a huge issue.
Once this analysis has been carried out, all we need to do is query the AST as needed to get size information at whatever granularity is desired (i.e. per function, per statement, per expression, etc.). Our preferred solution for this is the JSONPath library, which provides a convenient selector language for extracting speccific nodes from JSON-based data structures. The details of this portion are left as an exercise for the reader. You can also go check it out in the code for our implementation of this process, when it is released.
The Analyzer
Now that we've described how to carry out an analysis of contract size in principle, let us introduce our particular implementation of this technique, which we have named Sporalyzer.


Sporalyzer is a simple script that follows the approach described above in order to produce both a listing of Solidity functions and their respective bytecode sizes, as well as an 010 Editor script for rendering the contract bytecode with binary ranges highlighted and annotated to distinguish their corresponding source code.
The sorted list of functions by bytecode size allows for easy triage of functions that are the biggest contributors to contract size, while the 010 Editor script allows for more detailed and intuitive analysis of how this size actually manifests in the linear EVM bytecode. Both of these views are important for getting to the bottom of a variety of code size issues, as we will demonstrate.
A Test Drive
Let's run Sporalyzer on our contrived Ballot contract and take a look at the output. Below is the sorted list of functions by bytecode size:
Sum including Miscellaneous: 44386
Sum excluding Miscellaneous: 21630
[('GeneratedSources:abi_encode_tuple_t_uint256__to_t_uint256__fromStack_reversed',
7),
('GeneratedSources:abi_encode_tuple_t_address__to_t_address__fromStack_reversed',
9),
('GeneratedSources:abi_encode_tuple_t_bytes32_t_uint256__to_t_bytes32_t_uint256__fromStack_reversed',
12),
('GeneratedSources:abi_encode_tuple_t_stringliteral_0dc527e8fa9b76c996eb5eda9ddb749b21540f5509781b94e1e37f7027e7f50e__to_t_string_memory_ptr__fromStack_reversed',
18),
('GeneratedSources:abi_encode_tuple_t_stringliteral_56aab92b7164a4ea72a098d2d95a5e763b71d07f265e8d46fc7240404017fa84__to_t_string_memory_ptr__fromStack_reversed',
19),
('GeneratedSources:abi_encode_tuple_t_stringliteral_657c6119c4ed567c60278fba62242b17c2fedf38962e651040dabfb3c9e15a5f__to_t_string_memory_ptr__fromStack_reversed',
19),
('GeneratedSources:checked_add_t_uint256', 19),
('GeneratedSources:panic_error_0x32', 22),
('GeneratedSources:panic_error_0x11', 22),
('GeneratedSources:abi_encode_tuple_t_stringliteral_f37bf1aca80f8fa291a40f639db6aeaa1425ceb0e8c61c8648f0e2efa282a947__to_t_string_memory_ptr__fromStack_reversed',
23),
('GeneratedSources:abi_encode_tuple_t_stringliteral_8bd75322489f7ff7ab0b18506f4dcde935a32eca2a506b00f4d21b0becfa093c__to_t_string_memory_ptr__fromStack_reversed',
23),
('GeneratedSources:abi_encode_tuple_t_stringliteral_d39b1db28626750c546703ffb72f30ea3facdfed1bebd47408e22ef18a76ba2d__to_t_string_memory_ptr__fromStack_reversed',
23),
('GeneratedSources:abi_decode_tuple_t_uint256', 23),
('GeneratedSources:checked_mul_t_uint256', 23),
('GeneratedSources:increment_t_uint256', 24),
('GeneratedSources:abi_encode_tuple_t_uint256_t_bool_t_address_t_uint256__to_t_uint256_t_bool_t_address_t_uint256__fromStack_reversed',
27),
('GeneratedSources:abi_encode_tuple_t_stringliteral_80126ce3251ab2b6e4ade14fe5b2bc11f593510cbe9e3550c09bff1989e33b95__to_t_string_memory_ptr__fromStack_reversed',
28),
('Ballot:extraEntry19', 32),
('GeneratedSources:checked_div_t_uint256', 33),
('GeneratedSources:abi_decode_tuple_t_address', 37),
('Ballot:extraEntry14', 42),
('Ballot:largeConstsFuncViaMod', 46),
('Ballot:winnerName', 59),
('Ballot:giveRightToVote', 132),
('Ballot:winningProposal', 133),
('GeneratedSources:abi_encode_tuple_t_stringliteral_2122dfe2159b104c2c2fd64e829467dc587e5442cc6c0676f5fce22e2b27944e__to_t_string_memory_ptr__fromStack_reversed',
140),
('GeneratedSources:abi_encode_tuple_t_stringliteral_87cff5392f257ada4f5baf4221293e807322912f1ea4edbfd570ae62804ab840__to_t_string_memory_ptr__fromStack_reversed',
156),
('Ballot:vote', 171),
('Ballot:largeErrorStrings', 186),
('GeneratedSources:abi_encode_tuple_t_stringliteral_46d84fe6c027d2e8eb7894f1285f7b3972002615bf9a9c29c51cd8a60c1d4f44__to_t_string_memory_ptr__fromStack_reversed',
186),
('GeneratedSources:abi_encode_tuple_t_stringliteral_24c893151902cc2e506822843c81703d7d0e2e50c1180e77b807fcbff82d52c8__to_t_string_memory_ptr__fromStack_reversed',
220),
('GeneratedSources:abi_encode_tuple_t_stringliteral_2b82f021847a4c288e15a86185460a46da41f8297f97fba8117d856d351cc5df__to_t_string_memory_ptr__fromStack_reversed',
226),
('GeneratedSources:abi_encode_tuple_t_stringliteral_c44386d408b222105d53514b3fc0960b1b65d11920f301a69420b4f6c598688f__to_t_string_memory_ptr__fromStack_reversed',
256),
('GeneratedSources:abi_encode_tuple_t_stringliteral_ed3aa3883a002b2e644688c048d4cead3b1e26872d159f25683e0583b494b43b__to_t_string_memory_ptr__fromStack_reversed',
260),
('Ballot:delegate', 315),
('contracts/Ballot.sol Miscellaneous', 788),
('Ballot:largeConstsFunc', 1139),
('Ballot:largeConstsMod', 17520),
('Contract -1 Miscellaneous', 21968)]We can immediately notice a few things in this output. largeConstsFunc and largeConstsMod are both very high in the list, meaning that they almost certainly deserve some scrutiny. In our example case it should be fairly obvious why these functions are so large, since they were deliberately engineered to use many large constant values. But as we will see when we dig deeper, even this situation is more complex than it first appears. We can also see that largeConstsFuncViaMod and largeErrorStrings are actually not that large, which might seem a bit unintuitive. Clearly these will need more scrutiny as well.
We can also see some items in the list that are a bit harder to understand. The single largest item is something called Contract -1 Miscellaneous, which seems fairly mysterious. There's also contracts/Ballot.sol Miscellaneous, which is equally opaque. And furthermore, there's a whole bunch of entries that are attributed to some apparently non-existent file called GeneratedSources, which are perhaps even more inscrutable due to the very long function names, which were not present anywhere in the original source code.
Finally, we might have expected to see quite a bit of size attributed to all the excess entry points that we added, given that having too many entry points to the contract is often cited as a cause of over-large contracts. Yet we only see a few items that correspond to these extra entry points, and those items are actually fairly small.
We are starting to see where some of the contract size issues are coming from, but more investigation is needed to really get to the bottom of things. We will have to take a look at the 010 Editor rendering of the contract bytecode, to see if we can get a bit more insight into what's going on.
For those that are not familiar, 010 Editor is a hex editor that specializes in helping to impose structure on binary data, using a specialized scripting and templating language to add structure and annotations to what would otherwise be a sea of hard to understand binary data.
We want to do something similar with our contract bytecode, so we can better understand how the items from the list above are actually appearing in the linear bytecode. In order to do this, we wrote an EVM bytecode disassembler in the 010 Editor scripting language, and then had Sporalyzer emit an ad hoc 010 Editor template for our specific Ballot contract's bytecode, making use of this disassembler. Additionally, we made use of 010 Editor's ability to color different ranges of binary data to give different colors to ranges of bytecode that correspond to different regions of source code.

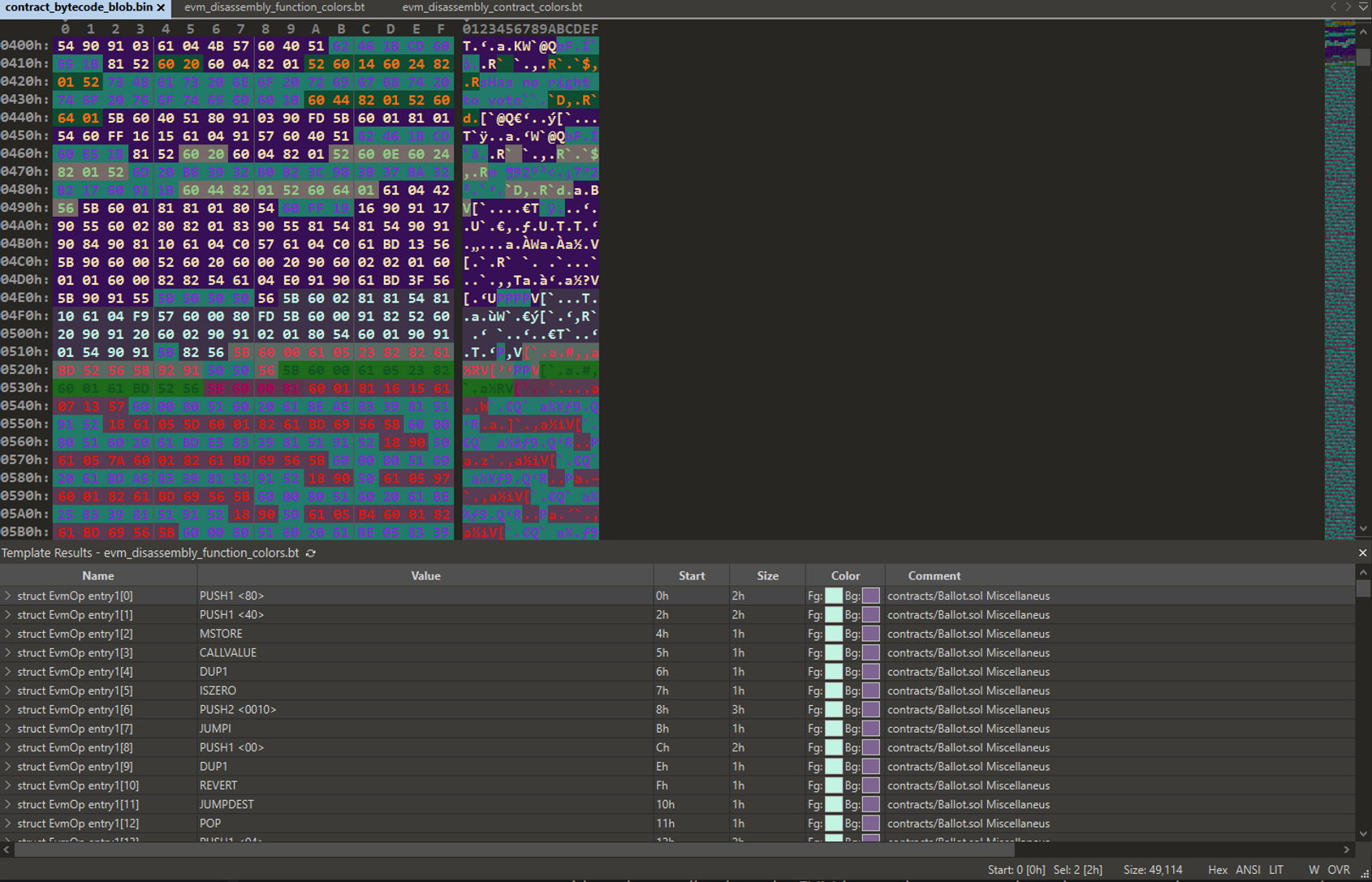
In the above screenshot you can see one version of the generated 010 Editor template being applied to the Ballot bytecode. In this version of the template, every function and modifier are given a unique color, to allow for an easy to interpret mid-level view of the source code responsible for each range of bytecode. We also have versions that can provide colorings at coarser (e.g. contract or file) or finer (e.g. scope block or statement) granularity.
In these pictures we can see quite a few different ranges of code, each annotated with its corresponding contract and function name in the comment column in the lower pane. Near the start of the contract we can see a lot of Ballot.sol Miscellaneous code, which corresponds to the initial dispatcher code that will decide where to go based on the passed function selector. Following that, we can start to see recognizable functions appear, such as `Ballot:vote'. We won't go through everything here, but you can start to see how this view of things really helps with understanding how the EVM bytecode corresponds to the source code at a very granular level.
Let's move forward a bit, and look for one of the functions that we identified as being quite large in the list from above. As we scroll down in the file, we notice a large region where two colors are very finely mixed together, with lots of short runs of each interspersed together. We can see by the annotations that these correspond to Ballot"largeConstsMod and File -1 Miscellaneous. We already know that both of these items were large contributors to the contract size, but now we can see that they are in fact very closely related. Indeed, if we pay closer attention to the dissasembly in the lower pane, we can see that the File -1 Miscellaneous code is almost always the same general bytecode sequence:

So what is going on here? Why is this same code from the mysterious File -1 showing up over and over again interspersed with Ballot:largeConstsMod code? Well, a clue to what is going on is the use of the CODECOPY EVM opcode. This opcode copies a value from somewhere else in the code, allowing some other part of the contract bytecode to be read as data. If we look back a few instructions before the CODECOPY, we can see the offset into the contract bytecode that will be used to fetch the data, and by looking at that offset, we find the bytes of one of our large constants. This means that rather than emitting the same large constant over and over again, solc decided that it would be more optimal to just store each large constant just once at the end of the contract bytecode, and then emit a sequence of bytecode that would fetch it using CODECOPY.
If we count carefully, we can see that this sequence of bytes for setting up and doing the CODECOPY is 15 bytes, whereas our large constants were 16 bytes each (ignoring leading zeroes), This means that the compiler has saved at least one byte per use of each constant, and in fact at least two once you remember that a PUSH16 would need an additional 17th opcode byte. It could be saving even more bytes, depending on whether any additional stack management instructions would be needed. This might not sound like a huge size savings, but over many uses of the same large constants, it does add up.
As an aside, while this optimization by the compiler did save a bit on size, it is actually a bit less gas efficient, since it needed quite a few more operations to actually get the constants from the contract bytecode. The difference is marginal, but it is interesting to see how the compiler chose that trade-off.
In any case, we have now gotten to the bottom of two mysteries: the File -1 item in our sorted size list, and the rapid back and forth mixing of two colors in our 010 Editor view of the contract. With regard to contract size, the conclusion that we arrive at is that the large constants being used in largeConstsMod are the root cause of both the Ballot:largeConstsMod and the File -1 Miscellaneous items in our sizes list. The use of these large constants would be a good thing to move to an external library, if possible.
With one issue identified, let us turn our gaze to the matter of large error strings. All the advice out there says that these error strings contribute to contract size, and indeed they must be in there somewhere, but why do we not see them as part of the size for the Ballot:largeErrorStrings entry in our list? Let's investigate further in 010 Editor by searching for the content of one of the error strings:

If we look at the annotation in the comment for this range, we see one of those long and inscrutable function names from earlier:
GeneratedSources:abi_encode_tuple_t_stringliteral_0e3dcbea00a00d5124ca5b890a2b3fc4690d46fc897a2256043132cf7f0658f8__to_t_string_memory_ptr__fromStack_reversedWe did note that these GeneratedSources functions were using up a bunch of space, while the largeErrorStrings function was using less than expected, and now we can see that these two facts are related. It turns out that solc will generate additional code for certain kinds of complex operations, including the materialization of large string constants, and rather than place this code directly in the original function, solc instead places it in its own functions. This is why they are from the apparently non-existent GeneratedSources contract.
If we look more closely at the build info JSON, we can actually find the source code that was generated for these functions, although it is written in the lower-level YUL intermediate representation language, rather than in Solidity. This is what differentiates GeneratedSources code from File -1 code; even though both are code generated by the compiler, one is generated as YUL code and treated as an additional input source file, while the other is ad hoc EVM bytecode generated later on in the compilation process.
So what conclusion do we draw from this? Well, it may be a bit anti-climactic, but the conclusion is that you just shouldn't use large error strings in your contracts, just like every other article on contract size will tell you. In this case our analyzer didn't offer us a novel solution. However, it did enable us to see exactly what the impact of the large error strings was, and in some situations where perhaps we hadn't realized they were there at all, like if they were pulled in by some library, our analyzer would have alerted us to their presence.
There are many more insights that can be gleaned from this lower-level view of the contract bytecode, but we hope that these small examples show some of the power and utility of this approach. Although there was never really any doubt as to where the contract size was coming from in our contrived example, some readers may still have been surprised about how things actually shook out at the bytecode level. And in the course of our development at Fungify we have encountered numerous cases where the sources of contract size were not nearly as straightforward or intuitive.
Sporalyzer has proven to be a valuable asset in our development process, to help us immediately pinpoint not only contract size issues, but also to help us understand our smart contracts at the lowest level to ensure that they are functioning as we expect.
The Future
As we have demonstrated, Sporalyzer is already a very useful tool, but there is always room for improvement. In the near future we plan to add things like integration with frameworks like Hardhat and Foundry, as well as a VS Code plugin for seeing the sizes of individual expressions in real-time.
We also have ideas for additional information and analysis that Sporalyzer can provide, like more detailed information about why certain generated code was added by solc, or the highlighting of particularly problematic code patterns. We can also provide more insight into the work of solc's optimizer, by giving information about things like inlining or constant folding. We already have some of these features provisionally added, and hope to include them in the final Sporalyzer release.
Conclusion
In conclusion, optimizing contract size is a critical concern for developers on the Ethereum platform, as it directly impacts the security and efficiency of smart contracts. While current approaches to contract size optimization have been limited and often rely on brute force methods, our new tool, Sporalyzer, offers a more precise and automated method to reduce contract sizes.
Sporalyzer will be open-sourced in our next follow-up post.
Update (04/03/2023):
The code for Sporalyzer, our contract analysis tool, is now open-sourced. Check it out here: https://github.com/0xMob100/sporalyzer
Notes
Waas, Markus, “Downsizing Contracts to Fight the Contract Size Limit.” Ethereum.org. https://ethereum.org/en/developers/tutorials/downsizing-contracts-to-fight-the-contract-size-limit/.
The Solidity Authors, “Using the Compiler.” Docs.soliditylang.org. https://docs.soliditylang.org/en/v0.8.19/using-the-compiler.html
The Solidity Authors, “Source Mappings.” Docs.soliditylang.org. https://docs.soliditylang.org/en/v0.8.19/internals/source_mappings.html
Seddon, Ryan, “Introduction to JavaScript Source Maps.” Developer.chrome.com. https://developer.chrome.com/blog/sourcemaps/
Since we are only concerned with the size of the contracts on chain after deployment we focus our efforts on the ‘deployedBytecode’ as opposed to the ‘bytecode’ which contains bytes relevant to creating the contracts such as constructors.